Domain Discovery Tool (DDT) Documentation¶
Domain Discovery is the process of acquiring, understanding and exploring data for a specific domain. Some example domains include human trafficking, illegal sale of weapons and micro-cap fraud. Before a user starts the domain discovery process, she has an “idea” of what she is looking for based on prior knowledge. During domain discovery, the user obtains additional knowledge about how the information she is looking for is represented on the Web. This new knowledge of the domain becomes prior knowledge, leading to an iterative process of domain discovery as illustrated in Figure 2. The goals of the domain discovery process are:
- Help users learn about a domain and how (and where) it is represented on the Web.
- Acquire a sufficient number of Web pages that capture the user’s notion of the domain so that a computational model can be constructed to automatically recognize relevant content.
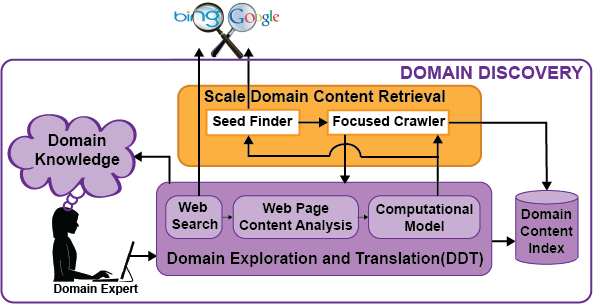
The Domain Discovery Tool (DDT) is an interactive system that helps explore and better understand a domain (or topic) as it is represented on the Web. It achieves this by integrating human insights with machine computation (data mining and machine learning) through visualization. DDT allows a domain expert to visualize and analyze pages returned by a search engine or a crawler, and easily provide feedback about relevance. This feedback, in turn, can be used to address two challenges:
- Assist users in the process of domain understanding and discovery, guiding them to construct effective queries to be issued to a search engine to find additional relevant information;
- Provide an easy-to-use interface whereby users can quickly provide feedback regarding the relevance of pages which can then be used to create learning classifiers for the domains of interest; and
- Support the configuration and deployment of focused crawlers that automatically and efficiently search the Web for additional pages on the topic. DDT allows users to quickly select crawling seeds as well as positive and negatives required to create the page classifier required for the focus topic.